The interactive and iterative process of
simulating real-world attacks to identify vulnerabilities in systems.
What kinds of systems?
PhysicalTechnicalHumanHybrid
Validates defensesRealistic assessment of how security controls stand up to true threats
Improves detectionIdentifies gaps in security monitoring and response times
Proactive risk reductionUncovers vulnerabilities before malicious actors do
Terminology
Red Team
Attackers — simulate adversaries, probe for weaknesses.
Blue Team
Defenders — detect, respond, harden the environment.
Purple Team
Collaboration — attackers & defenders working together in the open.
White-Box Testing
Full system information provided to the attacker — source code, architecture diagrams,
credentials, internal documentation.
Black-Box Testing
Only basic information provided — e.g. a company name or a public URL. The attacker
must discover everything else.
White Team / Cell — referee and oversight role; controls rules of engagement, adjudicates disputes
Pentesting vs. Red-Teaming
Penetration Testing
Scope
Narrow — a specific web app, API, or network segment.
Duration
Short — days to weeks.
Goals
Identify as many system vulnerabilities as possible; demonstrate compliance; patch technical flaws.
Awareness
Security team is usually aware of the test.
Red-Teaming
Scope
Broad — physical security, social engineering, full stack, people and process.
Duration
Long — weeks, months, or continuous.
Goals
Identify technical and other vulnerabilities; evaluate security processes and incident response; simulate advanced persistent threats (APTs).
Awareness
Security team may or may not be aware of the test.
Different tools for different questions.
Pentests answer "is this thing broken?"
Red teams answer "could we actually detect and stop a real adversary?"
The Red-Teaming Lifecycle
Common across frameworks (PTES, OWASP WSTG, MITRE, NIST)
0
Pre-planning & Scoping
1
Reconnaissance
2
Threat Modeling
3
Attack Planning
4
Execution, Movement & Iteration
5
Reporting & Debriefing
We'll walk through each step, then apply the same lens to AI systems.
Step 0
Pre-Planning & Scoping
Define objectives, goals, and rules of engagement.
What is the target system? (specific apps, networks, physical locations)
What system components are within scope?
What safety considerations exist? (production impact, customer data, legal constraints)
What red-team methods and behaviors are allowed, and which are out of bounds?
Establish communication, escalation, and oversight — who gets paged if
something breaks? Who has the authority to stop the exercise?
Step 1
Reconnaissance
Information gathering — learning the target without (yet) touching it.
OSINT
Open-source intelligence — what can you learn about the system without touching it? Public docs, DNS records, employee LinkedIn profiles, leaked creds, code on GitHub.
External Surveillance
How does the system behave externally? What response patterns, timings, and error messages leak information about internal architecture?
Map the External Attack Surface
Enumerate every public-facing component — domains, subdomains, APIs, login portals, ports, cloud assets, mobile apps, third-party integrations.
Step 2
Threat Modeling
Identify, enumerate, and analyze potential vulnerabilities.
?
What data or other systems are touched?
?
What actions can the system take on its own or on behalf of users?
?
What is the blast radius — potential scope of damage, disruption, or unauthorized access if the system is compromised?
Step 3
Attack Planning
Select attack targets — which vulnerabilities are you going to try, and in what order?
Build a test matrix of payloads and expected results.
Determine the attack sequence and phases — initial access, persistence, privilege escalation, lateral movement, exfiltration.
Step 4
Execution, Movement & Iteration
Launch attacks
Execute against the plan. Live environments surprise you.
Carefully document results
Every payload, every response, every timestamp. This becomes your report and your evidence.
Scan for newly emergent vulnerabilities
A foothold opens up a new interior attack surface — credentials, tokens, internal services.
Iterate and adapt
Your plan was a hypothesis. What actually works may be something you didn't anticipate.
Step 5
Reporting & Debriefing
Communicate findings with a well-written, professional report.
What goes in the report
Executive summary • methodology • findings ranked by severity • artifacts and diagrams • exploit evidence (screenshots, logs, PoCs) • timeline of the engagement
Recommend mitigations
Every finding gets a remediation. Be specific: technical controls, process changes, training, architectural redesign. Rank by impact vs. effort.
A great engagement with a bad report is a wasted engagement. The report is the deliverable.
Red-Teaming AI/ML Systems
Red-Teaming AI/ML systems
Simulating real-world attacks to identify vulnerabilities in
artificial intelligence systems and components.
How is Red-Teaming AI/ML systems different?
Probabilistic behavior
Outputs are non-deterministic. A payload that fails 9 times may succeed on the 10th. You test with distributions, not single shots.
Novel vulnerability classes
Biases, hallucination / confabulation, data leakage, harmful content generation, agentic misbehavior — categories traditional security doesn't cover.
Heterogeneous systems
Computer vision, recommenders, classifiers, autonomous control, generative models, agents. Different attack surfaces per system type.
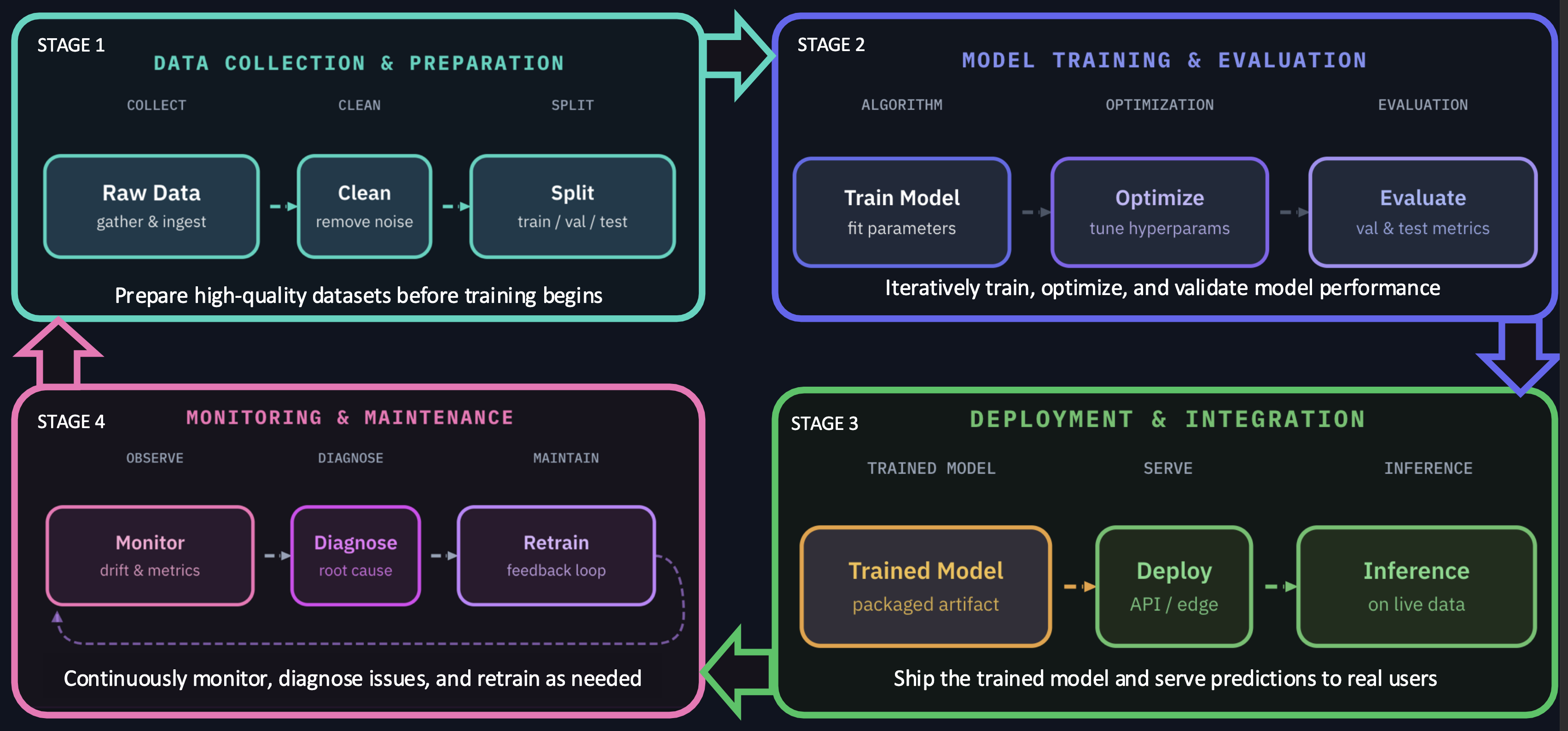
Lifecycle-wide attack surface
Testing must span the full AI/ML lifecycle: training data, model training, deployment, and inference-time behavior.
Red-Teaming AI/ML Systems (1 of 2)
Computer Vision
Recognition & detection
Adversarial Perturbation
Modify image pixels slightly to cause misclassification — often imperceptible to humans.
Data / Model Poisoning
Alter training datasets or inject backdoors; triggered inputs produce attacker-chosen predictions.
Tests the full agentic surface: pipelines, plugins, tools, inter-agent communication,
memory stores, and broader system dynamics — not just the model in isolation.
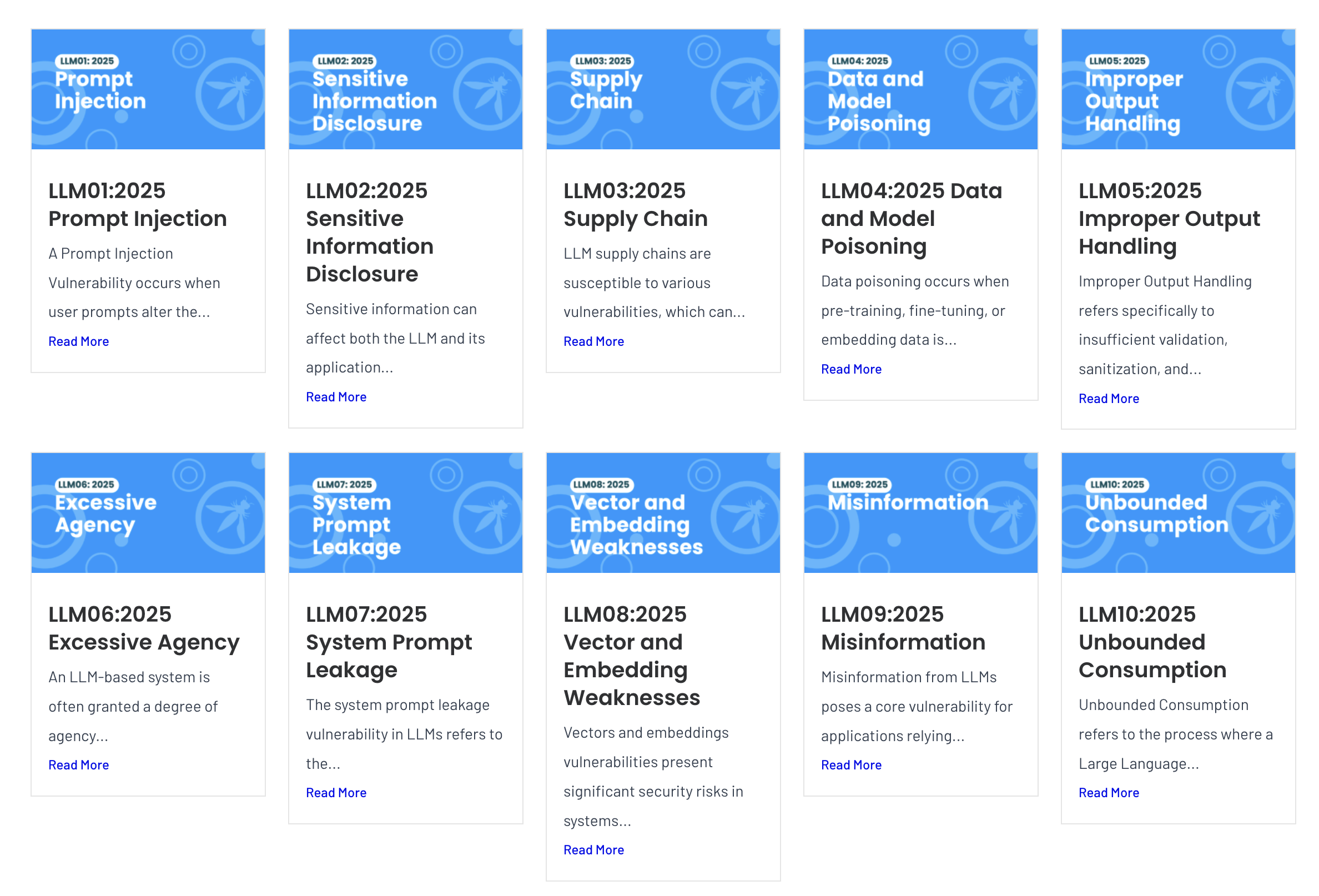
Prompt Injection — OWASP LLM01
A class of attacks against systems and applications built on top of LLMs that work by
concatenating untrusted input with trusted input.
Untrusted input shows up as: an attacker-controlled webpage the agent browses, a malicious
document it ingests, a poisoned tool response, a user-supplied file — anything the
agent treats as data but the model might treat as instructions.