1996




Governor of Massachusetts
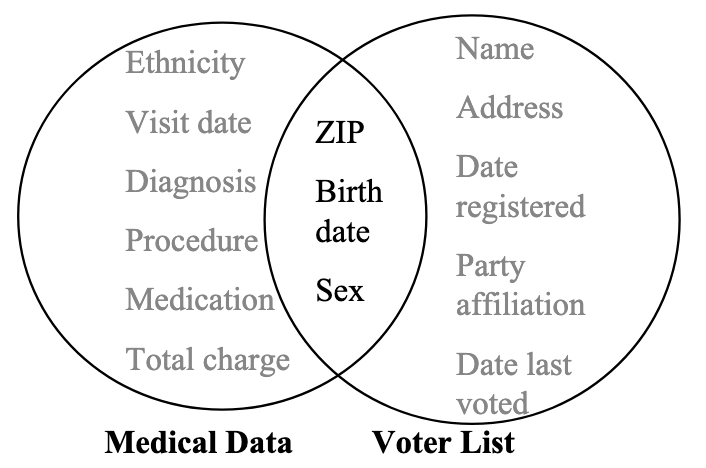
The internet is a toddler. Anonymization means taking a black marker to the obvious fields.
1996 — Setting the Scene
Ground the students in the era. The internet is new, spreadsheets are the primary tool, and the standard approach to "anonymization" is: delete names, delete addresses, delete Social Security numbers, and you're done.
This matters because the failure we're about to see isn't a failure of the people involved — they did what everyone thought was enough. It's a failure of the *assumption* that deletion equals anonymity.